Kode genetik
Kode genetik adalah sistem aturan yang digunakan sel untuk mengubah informasi dalam urutan DNA atau RNA (disusun dalam rangkaian tiga nukleotida, yang disebut kodon) menjadi protein. Proses ini terjadi dalam ribosom, yang menyusun protein dengan menghubungkan asam amino dalam urutan tertentu yang diberikan oleh RNA pembawa pesan (mRNA). RNA transfer (tRNA) membantu dengan membawa asam amino yang benar dan membaca urutan mRNA tiga nukleotida sekaligus.
Kodon adalah deret nukleotida pada mRNA yang terdiri atas kombinasi tiga nukleotida berurutan[1] yang menyandi suatu asam amino tertentu[2] sehingga sering disebut sebagai kodon triplet.[3] Asam amino yang disandikan misalnya metionin oleh urutan nukleotida ATG (AUG pada RNA).[3]
Banyak asam amino yang disandikan oleh lebih dari satu jenis kodon.[4] Kodon berada pada molekul mRNA.[5] Penerjemahan mRNA menjadi protein dilakukan pada ruas penyandi yang diapit oleh kodon awal (AUG) dan kodon stop (UAA, UAG atau UGA), ruas ini disebut gen.[6] Kodon pada molekul mRNA dapat menyandi asam-asam amino dengan bantuan interpretasi kodon oleh tRNA.[5] Setiap tRNA membawa satu jenis asam amino sesuai dengan tiga urutan nukleotida atau triplet yang disebut dengan antikodon yang berada pada simpul antikodon tRNA.[5] Antikodon mengikatkan diri secara komplementer pada kodon di mRNA, sehingga asam amino yang dibawa oleh tRNA sesuai dengan kodon yang ada pada mRNA.[5] pesan genetik ditransalsi kodon demi kodon dengan cara tRNA membawa asam-asam amino sesuai antikodon yang komplementer dengan kodon dan ribosom menyambungkan asam-asam amino tersebut menjadi suatu rantai polipeptida.[5] Ribosom menambahkan tiap asam amino yang dibawa oleh tRNA ke ujung rantai polipeptida yang sedang tumbuh.
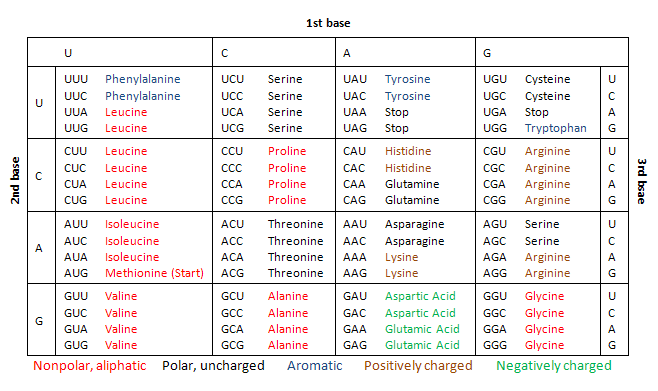
Kode genetik hampir sama pada semua organisme hidup dan dapat ditunjukkan dalam tabel dengan 64 kombinasi kodon, masing-masing menentukan asam amino tertentu atau menandakan akhir sintesis protein. Meskipun sebagian besar organisme menggunakan kode genetik standar ini, ada beberapa pengecualian, seperti pada mitokondria.
Sejarah
suntingUpaya untuk memecahkan kode bagaimana protein dikodekan dimulai setelah penemuan struktur DNA pada 1953. Tokoh kunci dalam bidang ini adalah Francis Crick, seorang ahli biofisika Inggris, dan James Watson, seorang ahli biologi Amerika, yang bekerja bersama di Universitas Cambridge. Mereka berhipotesis bahwa informasi genetik mengalir dari DNA dan DNA memainkan peran kunci dalam pembentukan protein. Fisikawan Soviet-Amerika, George Gamow, adalah orang pertama yang mengusulkan model yang dapat diterapkan, yang menunjukkan bahwa kelompok tiga basa DNA, atau kembar tiga, dapat mengkodekan 20 asam amino standar yang dibutuhkan untuk membangun protein. Pendekatan ini, dengan menggunakan kombinasi empat basa untuk menghasilkan 64 kemungkinan kodon, menjadi dasar dari kode genetik. Gamow menyebut hubungan DNA-protein ini sebagai “kode berlian”.
Ciri
suntingBingkai pembacaan
suntingBingkai pembacaan (reading frame) dalam DNA atau RNA ditentukan oleh triplet nukleotida awal yang menjadi titik awal penerjemahan. Kodon awal ini mengatur tahap untuk triplet yang tidak tumpang tindih berikutnya, yang disebut kodon, dalam urutan yang dikenal sebagai “bingkai pembacaan terbuka” (ORF). Sebagai contoh, urutan 5'-AAATGAACG-3' dapat dibaca dengan tiga cara yang berbeda, tergantung dari mana pembacaan dimulai. Jika dibaca dari nukleotida pertama, maka akan menghasilkan kodon AAA, TGA, dan ACG. Jika pembacaan dimulai dari nukleotida kedua atau ketiga, kumpulan kodon yang berbeda akan terbentuk. Ini berarti satu urutan tunggal dapat menghasilkan rantai asam amino yang berbeda tergantung pada bingkai pembacaan. Pada DNA untai ganda, ada enam bingkai pembacaan potensial: tiga ke arah depan pada satu untai dan tiga ke arah belakang pada untai komplementer.
Bingkai pembacaan kode protein biasanya dimulai pada kodon AUG (dalam RNA) atau ATG (dalam DNA) pertama, yang menandakan dimulainya penerjemahan. Pada eukariota, ORF pengkodean protein sering kali terganggu oleh urutan non-pengkodean yang disebut intron, yang harus dihilangkan untuk mendapatkan urutan mRNA akhir.
Kodon awal dan kodon stop
suntingKodon awal merupakan kodon pertama yang diterjemahkan pada saat translasi atau disebut juga kodon inisiasi (AUG yang menyandikan metionin).[7] Selain kodon inisiasi, untuk memulai translasi diperlukan juga sekuen atau situs yang disebut Shine-Dalgarno untuk pengenalan oleh ribosom yang juga dibantu oleh faktor inisiasi (berupa tiga jenis protein).
Menurut Gordon et al. (2019), kodon stop merupakan salah satu dari tiga kodon, yaitu UAG, UAA atau UGA.[8] Kodon stop disebut juga kodon terminal yang tidak menyandikan asam amino.[8] Kodon stop menyebabkan proses translasi berakhir dengan bantuan faktor pelepasan untuk melepas ribosom.[8]
Kode genetik alternatif
suntingAsam amino non-standar
suntingAsam amino non-standar terkadang dapat menggantikan kodon stop standar dalam protein, tergantung pada urutan sinyal tertentu dalam mRNA. Sebagai contoh, kodon stop UGA dapat mengkodekan selenosistein, dan UAG dapat mengkodekan pirrolisin. Selenosistein sering disebut sebagai asam amino ke-21, sedangkan pirrolisin dianggap sebagai asam amino ke-22. Menariknya, kedua asam amino non-standar ini dapat ditemukan dalam organisme yang sama. Meskipun kode genetik biasanya stabil dalam suatu organisme, prokariota tertentu seperti archaeon Acetohalobium arabaticum dapat memperluas kode genetik mereka untuk memasukkan pirrolisin, meningkatkan jumlah asam amino yang digunakan dari 20 menjadi 21, tergantung pada kondisi pertumbuhan.
Variasi
suntingAwalnya, kode genetik diyakini bersifat universal, berdasarkan gagasan bahwa variasi apa pun akan mematikan bagi suatu organisme, yang disebut teori “kecelakaan beku”. Namun, pada 1968, Francis Crick menyatakan bahwa keuniversalan kode genetik di seluruh organisme tidak terbukti dan kemungkinan besar tidak mutlak. Dia memperkirakan kode tersebut akan menjadi “universal atau hampir universal.” Variasi pertama dalam kode genetik ditemukan pada 1979 pada gen mitokondria manusia, dan lebih banyak lagi varian kecil yang ditemukan setelahnya, termasuk kode mitokondria alternatif.
Misalnya, pada spesies Mycoplasma, kodon UGA diterjemahkan sebagai triptofan, bukan sebagai kodon stop, dan pada ragi tertentu, kode CUG untuk serin, bukan leusin. Virus, yang bergantung pada mesin genetik inang, umumnya mengikuti kode genetik inang, tetapi beberapa, seperti totivirus, telah beradaptasi dengan modifikasi kode pada inangnya. Pada bakteri dan arkea, GUG dan UUG sering digunakan sebagai kodon awal, dan dalam kasus yang jarang terjadi, kodon awal alternatif digunakan pada protein tertentu.
Menariknya, variasi dalam kode genetik juga ditemukan pada gen yang dikodekan oleh nuklir manusia. Pada 2016, para peneliti menemukan bahwa sekitar 4% dari mRNA yang mengkode malat dehidrogenase menggunakan kodon stop untuk mengkodekan triptofan dan arginin, sebuah fenomena yang disebut pembacaan translasi fungsional.
Terlepas dari variasi ini, semua kode genetik yang diketahui mengikuti mekanisme dasar yang sama: kodon yang terdiri dari tiga basa, tRNA, ribosom, dan pembacaan dalam satu arah. Namun, variasi ekstrem telah ditemukan pada ciliata, di mana arti kodon stop tergantung pada posisinya dalam mRNA.
Asal-usul dan evolusi kode genetik telah dipelajari secara ekstensif, dan beberapa penelitian bahkan melibatkan evolusi kode genetik secara eksperimental pada organisme.
Inferensi
suntingVarian kode genetik yang digunakan oleh organisme dapat ditentukan dengan menganalisis gen yang sangat lestari dalam genom mereka dan membandingkan penggunaan kodon dengan asam amino yang ditemukan dalam protein homolog dari organisme lain. Sebagai contoh, program FACIL menyimpulkan kode genetik dengan memeriksa asam amino mana dalam domain protein yang serupa yang sesuai dengan setiap kodon. Probabilitas yang dihasilkan untuk setiap kodon, apakah sesuai dengan asam amino atau kodon stop, secara visual diwakili dalam logo kode genetik.
Pada Januari 2022, survei kode genetik yang paling komprehensif dilakukan oleh Shulgina dan Eddy, yang menganalisis 250.000 genom prokariotik menggunakan alat Codetta. Alat ini bekerja mirip dengan FACIL tetapi menggunakan basis data Pfam yang lebih besar. Meskipun NCBI telah menyediakan 27 tabel terjemahan, para penulis mengidentifikasi lima variasi baru kode genetik, yang didukung oleh mutasi tRNA, dan mengoreksi beberapa kesalahan penafsiran sebelumnya. Codetta juga telah digunakan untuk mempelajari perubahan kode genetik pada ciliata.
Kegunaan
suntingSintesis protein
suntingKode genetik membawa informasi tentang urutan asam amino yang dibutuhkan oleh protein. Informasi ini dibawa oleh gen tertentu. Jenis informasi yang berada di dalam kode genetik berupa cara pengkodean urutan nukleotida pada DNA atau RNA untuk menentukan urutan asam amino pada saat sintesis protein. Basa nitrogen menentukan informasi di dalam kode genetik pada rantai DNA yang akan menentukan susunan asam amino.[9]
Referensi
sunting- ^ (Inggris) Anthony JF Griffiths, Jeffrey H Miller, David T Suzuki, Richard C Lewontin, and William M Gelbart (2000). An Introduction to Genetic Analysis. University of British Columbia, University of California, Harvard University (edisi ke-7). W. H. Freeman. hlm. Genes as determinants of the inherent properties of species. ISBN 0-7167-3520-2. Diakses tanggal 2010-08-17.
- ^ (Inggris) Anthony JF Griffiths, Jeffrey H Miller, David T Suzuki, Richard C Lewontin, and William M Gelbart (2000). An Introduction to Genetic Analysis. University of British Columbia, University of California, Harvard University (edisi ke-7). W. H. Freeman. hlm. Glossary - Codon. ISBN 0-7167-3520-2. Diakses tanggal 2010-08-17.
- ^ a b Yuwono T. 2005. Biologi Molekuler. Jakarta: Erlangga.
- ^ (Inggris)Dale JW & Park SF. 2004. Molecular genetics of Bacteria. Chichester: John Willey & Sons Ltd.
- ^ a b c d e Campbell NA, Reece BJ, Mitchell LG. 2002. Biologi. Jakarta: Erlangga
- ^ Jusuf M. 2001. Genetika I: Struktur dan Ekspresi Gen. Jakarta: Sagung Seto
- ^ (Inggris)Touriol C, Bornes S, Bonnal S, Audigier S, Prats H, Prats AC, Vagner S. 2003. Generation of protein isoform diversity by alternative initiation of translation at non-AUG codons. Biol. Cell 95 (3-4): 169–78
- ^ a b c (Inggris)Maloy S. 2003. Microbial Genetics Course. San Diego University
- ^ Susilawati dan Bachtiar, N. (2018). Biologi Dasar Terintegrasi (PDF). Pekanbaru: Kreasi Edukasi. hlm. 156. ISBN 978-602-6879-99-8.
Artikel ini tidak memiliki kategori atau memiliki terlalu sedikit kategori. Bantulah dengan menambahi kategori yang sesuai. Lihat artikel yang sejenis untuk menentukan apa kategori yang sesuai. Tolong bantu Wikipedia untuk menambahkan kategori. Tag ini diberikan pada Januari 2023. |